

Why Self-Supervised Encoders Want to Be Normal
Read the full paper here: https://arxiv.org/abs/2604.27743
Self-supervised learning has achieved remarkable empirical success in learning robust representations without explicit labels, most recently demonstrated within the framework of Joint-Embedding Predictive Architectures (JEPA).
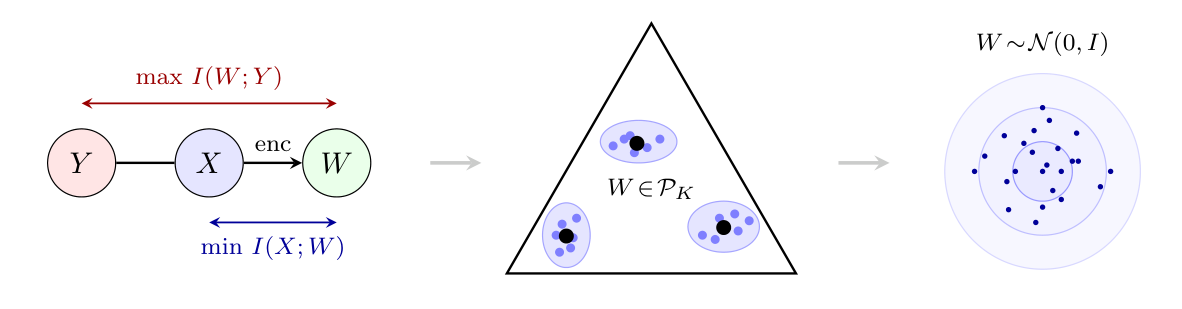
However, a fundamental question remains: what analytical principles drive these encoders toward specific distributional states? In this paper, we demonstrate that the preference for normal distributions in self-supervised encoders is a direct consequence of the Information Bottleneck (IB) principle. By recasting the IB objective as a rate-distortion problem over the predictive manifold, we provide a theoretical basis for why optimal, target-neutral, latent representations should tend towards isotropic Gaussian states.
Under this framework, we show that latent representations correspond to soft clustering of inputs sharing similar predictive distributions, organized within a natural simplex structure. This perspective unifies a wide range of existing supervised and less-supervised objectives and provides a principled explanation for commonly used regularization schemes. Furthermore, we derive practical loss objectives that approximate this structure and demonstrate their effectiveness on standard benchmarks. Ultimately, our framework offers a geometric lens to understanding representation collapse and it establishes a mathematical system for regularization strategies to be used to ensure high-entropy, informative embeddings in modern self-supervised models.
Read the full paper here: https://arxiv.org/abs/2604.27743