
LiteAttention: Optimized Quantization
This post walks through the core ideas behind LiteAttention v0.4 quantization stack, with a focus on a novel INT32 to FP32 conversion and scheduling strategy that removes a major bottleneck.
TL;DR
- Try LiteAttention: https://github.com/moonmath-ai/LiteAttention
- Learn more about LiteAttention: https://moonmath.ai/posts/liteattentionnintro/
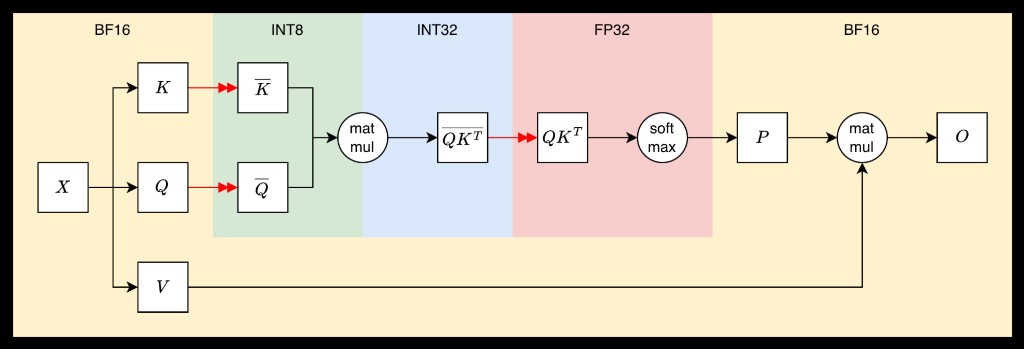
- LiteAttention v0.4 uses a hybrid INT8-BF16-FP32 attention stack matched to the statistical structure of attention.
- A constrained-range INT32 to FP32 trick plus dual-flow scheduling removes a major quantized softmax bottleneck.
Quantization That Matches Attention Internals
We follow the hybrid INT8-BF16 quantization scheme used in SageAttention:
- Q, K -> INT8
- Accumulation -> INT32
- Softmax -> FP32
- P, V, Output -> BF16
At a high level, INT8 is used where values are approximately Gaussian with limited range, BF16 is used where values are log-distributed (softmax outputs), and FP32 is used only where strictly required for softmax stability.[1] (This is not arbitrary: it matches the statistical structure of attention.)
Why INT8 works for Q/K
After layer norm, Q/K values have mean ~ 0, variance ~ 1, and lie almost entirely within [-4, 4]. This makes floating-point overkill. Integer quantization provides uniform precision where it matters, avoids wasted exponent range, and significantly reduces memory and bandwidth.
Tile-wise quantization
Quantization is done per tile, not globally: we normalize the tile so max absolute value = 1, scale to INT8, and store the scale for later dequantization. Then QK is computed in INT8, accumulated into INT32 registers, and later dequantized into FP32 before softmax.
The Bottleneck: INT32 -> FP32
Once QK is computed, each element is an INT32 dot product. Before softmax, we must convert: INT32 -> FP32
This conversion, which translates into a SASS instruction returning 64 results per cycle, creates an overhead that does not exist when working with FP8. This becomes a dominant cost in the quantized attention.
The Int-to-Float Trick
The INT32 accumulator is not arbitrary. Given INT8 inputs and head size <= 256,
The dot product range is: s ∈ [-2^22 + 2^15, 2^22]
So effectively only ~23 bits are needed, far smaller than full INT32.
This constraint is what unlocks everything. Instead of a full conversion, we exploit IEEE-754 structure. We use a magic constant:
M = 2^23 + 2^22 - 1Then:
s_fp32 = float(s + M) - float(M)And the basic code looks like this:
float int2float(int s){
constexpr float magic_float = float((1 << 23) + (1 << 22) - 1);
constexpr int magic_int = reinterpret_bits<int>(magic_float);
float s_float = reinterpret_bits<float>(s + magic_int) - magic_float;
return s_float;
}Why this works:

FP32 mantissa has 23 bits, adding M shifts integer bits into the mantissa, and subtraction restores the correct value in FP space.
Purplesyringa’s blog post provides a good exposition of this idea. Here we just defined a new magic number to fit our range. We ended up replacing the native conversion with 1 integer add, 1 float add, and a reinterpret cast.
Folding the Conversion into Softmax
We can go further. Instead of computing:
s_float = int2float(s)
p = s_float * log2e - max_scaled
Which requires three additions: two for int2float(s) and one for p. We inline and define s_almost_float where magic_int is a constant defined once and not for every s.[2] (This removes one subtraction.)
s_almost_float = reinterpret_bits<float>(s + magic_int)
p = s_almost_float * log2e - (max_scaled + magic_float * log2e)Final cost per element: 1 integer add, 1 FFMA (which we do either way), and 0 explicit conversions.
This turns conversion into something the compiler can map to fully pipelined instructions.
Can we do better? Yes!
Dual-Flow Interleaving
Note that the new kernel now becomes FP-pipeline bound. Naively, the loop looks like:
I2FP -> FMAX -> I2FP -> FMAXThis overloads FP units and conversion units, and creates scoreboard stalls.
We do not need to compute max in FP space for every value.
We introduce two parallel flows:
Flow A: Standard Path
int32 -> FP32 -> float maxUses I2FP and FMMNX.
Flow B: Integer Emulation Path
int32 -> transformed int -> int max -> (interpreted as float later)Uses integer add with the magic constant and integer max (VIMNMX3).[3] (This works because the transformation preserves ordering equivalent to FP32, so integer max is a valid surrogate for float max.)
Interleaving the Two Flows
Instead of processing one stream, We process two interleaved streams:
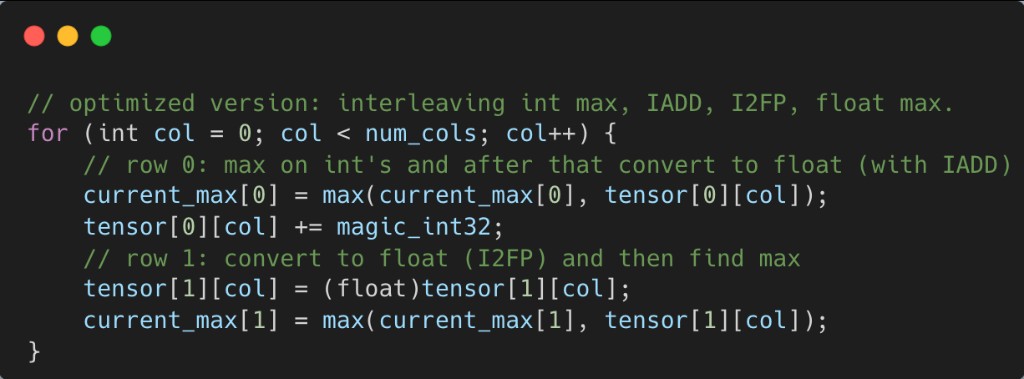
Now Flow A uses FP and convert pipelines, while Flow B uses INT pipelines. This enables dual-issue, latency hiding, and better warp scheduling.[4] (The SASS reflects this: VIADD and VIMNMX3 on the INT pipeline, together with I2FP and FMMNX on the FP pipeline, instead of only FP instructions.)
This changes the kernel regime. Before, it was conversion-bound, the FP pipeline was saturated, and stalls were frequent. After, INT and FP utilization is more balanced, dependencies are fewer, and instruction throughput is higher.
Combined with the fast int2float trick, INT32 -> FP32 plus reduction becomes more than 2x faster and overall running time improves by 3%-4%.
Try LiteAttention: https://github.com/moonmath-ai/LiteAttention