
Introducing BackLite: Attention Backpropagation Acceleration Using Dynamic Sparsity
TL;DR
- Try it now: https://github.com/moonmath-ai/BackLite
- BackLite speeds up transformer training by tracking attention sparsity in the forward pass and reusing it to skip work in the backward pass.
- It approximates full-attention gradients while preserving training behaviour closely in early experiments.
BackLite is a novel algorithm which dynamically discovers and exploits the sparsity of the attention matrix to speed up the backward pass while mathematically approximating the attention gradients.
Introduction
Transformer-based architectures have become the dominant backbone for a wide range of generative models, from large language models (LLMs) to video diffusion transformers (DiTs). At the heart of these architectures lies the self-attention layer. Self-attention requires computing the inner products between all pairs of queries and keys, resulting in quadratic computational complexity with respect to the context or sequence length. This quadratic scaling severely limits the training of large models, especially for video diffusion transformers (DiTs) and large language models (LLMs).
The problem with large sequence lengths is most acutely seen in video diffusion models like Wan 2.1[1], where generating a 5s 480p video requires 32k tokens and generating a 5s 720p video, similarly, requires 75k tokens.
On the other end, LLMs are usually first trained with “small” context lengths (2-8k) and then their contexts are extended to much larger values (128k+) during a context extension phase, which is shorter than the low-context-length phases. Even then, the backward pass through attention forms a major chunk of the training workload. Attention overhead compared to the FFN and linear layers during training is 16% for context lengths of 8k and it grows to 260% for context lengths of 128k.[2]
It is well known that the attention matrix is usually highly sparse. Several works[3][4][5][6] have utilised this high sparsity for speeding up the attention forward pass. The backward pass through attention is 2-3x more expensive than the forward pass. In this work, we present the first algorithm to use this sparsity for speeding up the backward pass for full attention, as opposed to structural sparsity imposed by a radial or local attention mask.
BackLite is a novel algorithm designed to exploit the sparsity inherent in attention to skip computation while mathematically approximating the gradients through the attention layer. Our idea:
Simply track the sparsity in the attention matrix during the forward pass and use it to skip computation during the backward pass.
Since this idea is independent of the model and its use case, autoregressive or diffusion, BackLite is expected to speed up the training of all transformer-based models.
Backpropagation for attention
During backpropagation through a layer, one needs to compute the gradient of the loss function with respect to the inputs given the gradient of the loss with respect to the output. For this, one typically first computes the forward pass through the entire network, records any helpful intermediate results for the backward pass, and then uses these results to compute the backward pass through each layer.
Let us begin by considering a single attention head to understand the backpropagation equations and how we use sparsity to speed up backprop.
In the forward pass for attention, we are given the inputs \(Q, K, V \in \mathbb{R}^{n \times d}\), where \(n\) is the sequence length (total number of tokens) and \(d\) is the head dimension. The output \(O \in \mathbb{R}^{n \times d}\) is given according to the following equations:
\[ \begin{aligned} S &= \frac{Q K^{\top}}{\sqrt{d}} \\ P &= \operatorname{softmax}(S) \quad \text{(row-wise)} \\ O &= P V. \end{aligned} \]
\(S\) (score matrix) and \(P\) (attention matrix) above are \(n \times n\) size intermediate matrices. One has to be careful to not completely materialize these matrices during the forward pass, as their size quickly explodes and consumes GPU memory, in addition to slowing down attention kernels. In fact, this is the central observation used in the design of FlashAttention (FA).[7][8]
For backpropagation, we will denote the gradient of the loss with respect to the variable \(X\) using the variable \(G_X\).
During the attention backward pass, we are given the gradient \(G_O\) (derivative of the loss with respect to the output \(O\)) in addition to \(Q\), \(K\), \(V\), and \(O\), and we are asked to compute the gradients \(G_Q\), \(G_K\), and \(G_V\). The equations for the backward pass are given as:
\[ \begin{aligned} G_V &= P^{\top} G_O \\[0.5em] G_P &= G_O V^{\top} \\[0.5em] D &= \operatorname{diag}(G_O O^{\top}) \\[0.5em] G_S &= G_P \odot P - \operatorname{diag}(D)\, P \\[0.5em] G_Q &= \frac{G_S K}{\sqrt{d}} \\[0.5em] G_K &= \frac{G_S^{\top} Q}{\sqrt{d}} \end{aligned} \]
where \(P\) is once again the attention matrix and \(\odot\) is the elementwise product. The gradients \(G_P\) and \(G_S\) above are also \(n \times n\) intermediates, which FA carefully avoids fully materializing or storing. The flow of these gradients is depicted in Fig. 1.
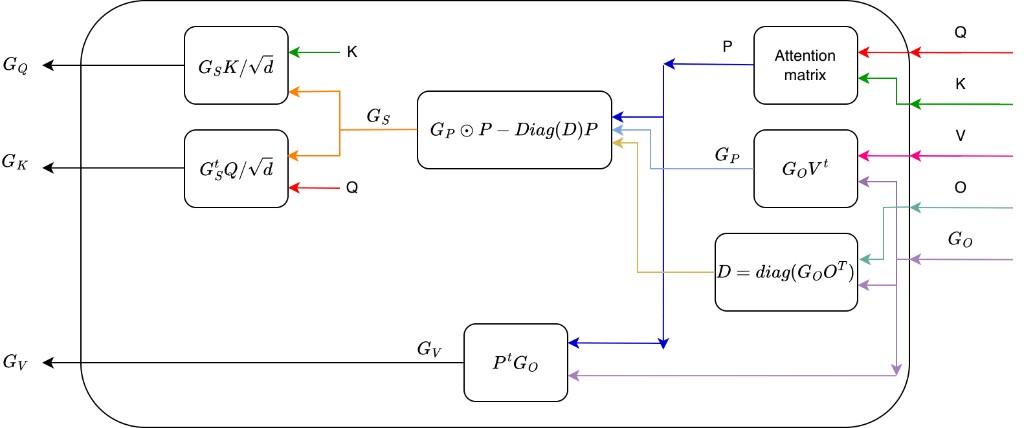
During the forward pass, we also have the additional freedom of storing any reasonably sized intermediate results, which can help during the backward pass. The FA forward pass, for example, stores certain statistics useful for normalising the attention matrix \(P\). We will use this freedom to store a sparsity mask during the forward pass.
Using Sparsity
For our work, we build on the FA algorithm, specifically on our LiteAttention kernels. Our idea for using sparsity during the backward pass is to compute the forward pass exactly, while recording the positions of the negligible attention matrix values for the backward pass. Then, during the backward pass we mask out these elements in the attention matrix and save on the cost of computing these entries and performing any downward computations with them.
In more detail, note that if we know that the attention matrix entry \(P_{ij} \approx 0\) for some \((i, j)\), then we can skip the multiplications with this element in the calculation for \(G_V = P^{\top} G_O\). Also, note that \(P_{ij} \approx 0\) implies that \((G_S)_{ij} \approx 0\) (as long as \(G_P\) and \(D\) are well behaved, which happens to be the case). So the sparsity of \(P\) translates exactly to the sparsity of \(G_S\), and if we have a mask of elements to skip in \(P\) for sparsity, we can simply use that same mask during the computation of \(G_S\) and its multiplications with \(Q\) and \(K\). Our algorithm is built on this observation.
We further modify the algorithm to make it more compatible with the structure of FA. The FA forward-pass algorithm computes the attention matrix \(P\) in tiles. In BackLite, we record the "weight" of the tile \(\sum_{(i,j)\in \text{tile}} P_{ij}\) during this forward pass, in addition to the usual FlashAttention computations. During the backward pass, we use these tile weights to create a mask by neglecting the smallest weighted tiles summing to a small fraction of the total weight in the attention matrix. This provides us with a mask of tiles we can skip computing during the backward pass. If a tile is skipped, then all computation and memory loads corresponding to it can be skipped as well, and we can simply move to the next tile. Thus, sparsity directly translates to computational savings. We see this in the performance of our kernels as well, where sparsity translates directly to gains during the backward pass.
Experiments
We can tune the weight of the attention matrix that is neglected. We can also compare the gradients produced by the exact FA backprop against the ones produced by BackLite for different values of this parameter. In our experiments, setting this parameter at just 1% resulted in a sparsity of \(\sim 30\%\) in the Wan 2.1 1.3b model and we observed that the gradients at the end of each of the attention layers had cosine similarities of \(1.00\) (up to floating point errors) and relative L2 differences of \(\sim 3\%\).
We will be releasing these results and more soon. Today we would like to show the results of using our algorithm for training Nanochat and the preliminary results with Wan 2.1 1.3b.
Preliminary results with Wan 2.1 1.3b
We used our algorithm to train a (bad) checkpoint of Wan 2.1 1.3b model (batch size=16, learning rate= 5e-5) for around 2k steps. While neglecting just 1% of the attention matrix weight, we see sparsity in excess of 30%. The loss curve for training with this parameter can be seen in Fig. 2.
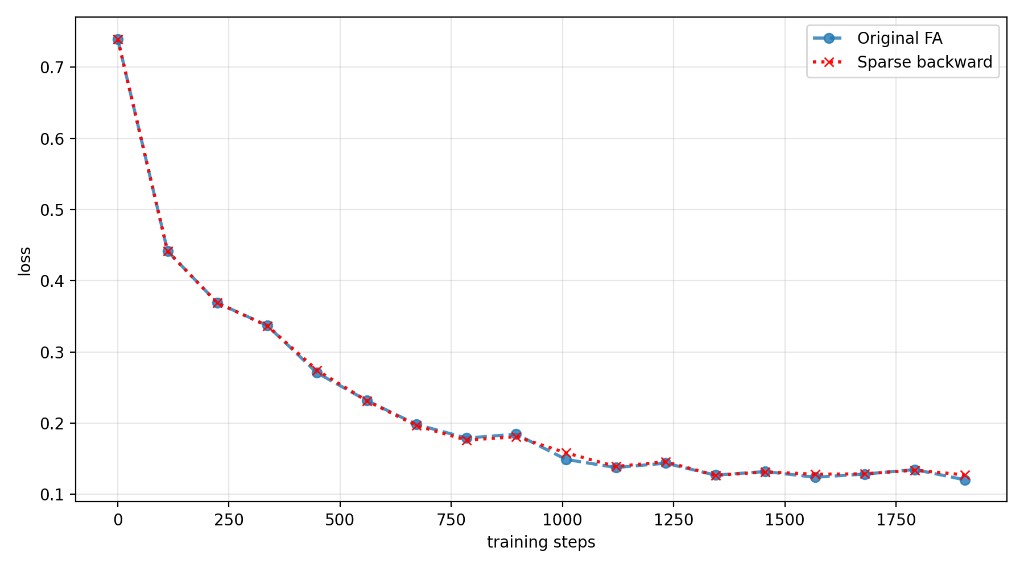
We also created a calibration tool to calibrate the weight neglected during BackLite in each epoch to target a minimum cosine similarity and a maximum relative L2 difference. We use our tool with relatively loose settings (cosine similarity >0.99 and relative L2 difference <0.1) and see sparsities in excess of \(50\%\). Interestingly, the loss curve still follows the original very closely.
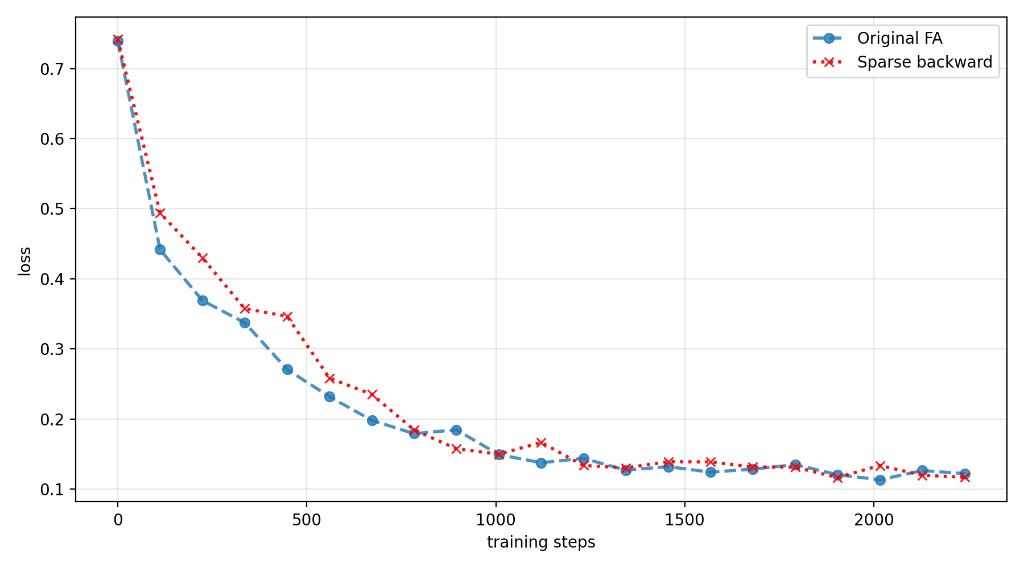
As we increase the batch size for the optimisation, we expect to see lower differences between the original FA backward pass and BackLite.
Check it out: https://github.com/moonmath-ai/BackLite