
Journey From Wan to Decart LSD, Part1: FrameCommit
TL;DR
- Real-time video systems need low latency per pixel frame, not just high aggregate FPS.
- Modern latent video models like Wan compress time, so one AR step usually emits multiple pixel frames at once.
- FrameCommit proposes conditioning the model on partially committed pixel frames so it can emit one frame per step while keeping a 3D VAE backbone.
In July 2025 Decart introduced MirageLSD, the first live-stream diffusion AI video model. This model, built on a custom model called Live Stream Diffusion, enables frame-by-frame generation while preserving temporal coherence. We recently asked ourselves, what will be cheapest, most efficient way to train such a model. This led us into a fun rabbit hole, one which we are still exploring. In this first part we are proposing a solution to how to bypass the pixel-to-latent compression of existing video models VAEs to generate one pixel frame per AR step.
The Goal
What we want to achieve is the system in the image below: a camera takes real-time input and a video model generates a stylized or transformed output based on this input.
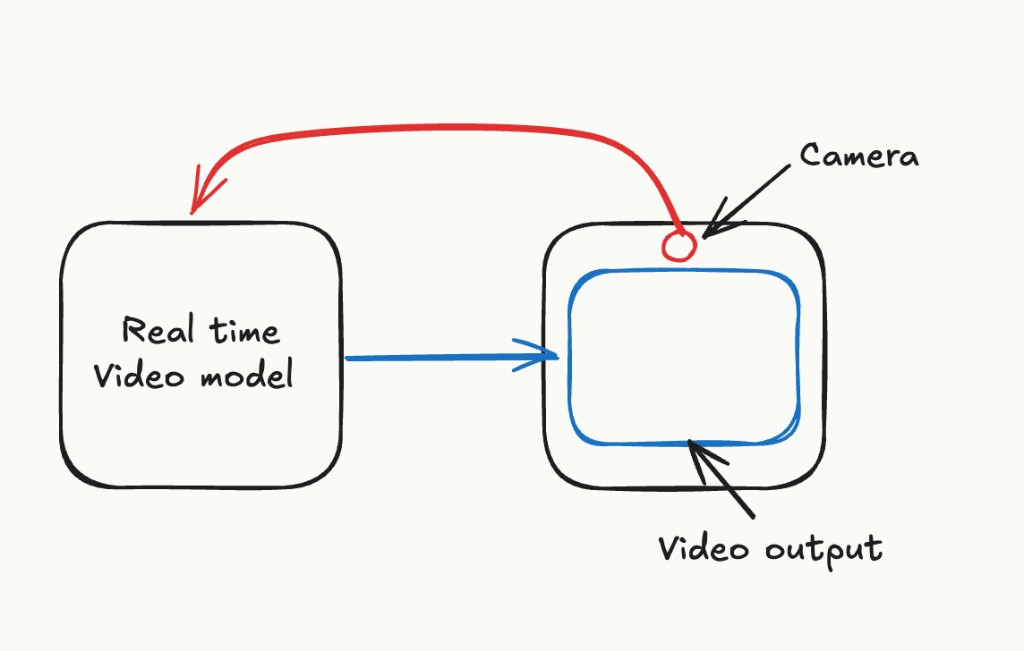
The fundamental challenge in designing such a model is ensuring that the latency between pixel frames is imperceptible. We want our model to respond immediately to camera input, or with minimal latency. A lot of existing work in the video generation space conflates latency and throughput when reporting FPS numbers.
What we would like to achieve with a 25 FPS video generation model is pixel frames appearing with a latency of 40ms (= 1s / 25), with each pixel frame incorporating the camera input from the previous time step. Decart’s MirageLSD claims to achieve this, describing multiple algorithmic and engineering techniques in their technical report and blog. These include shortcut distillation, mega kernels, and architecture-aware pruning. We’ll go into these techniques in more detail later.
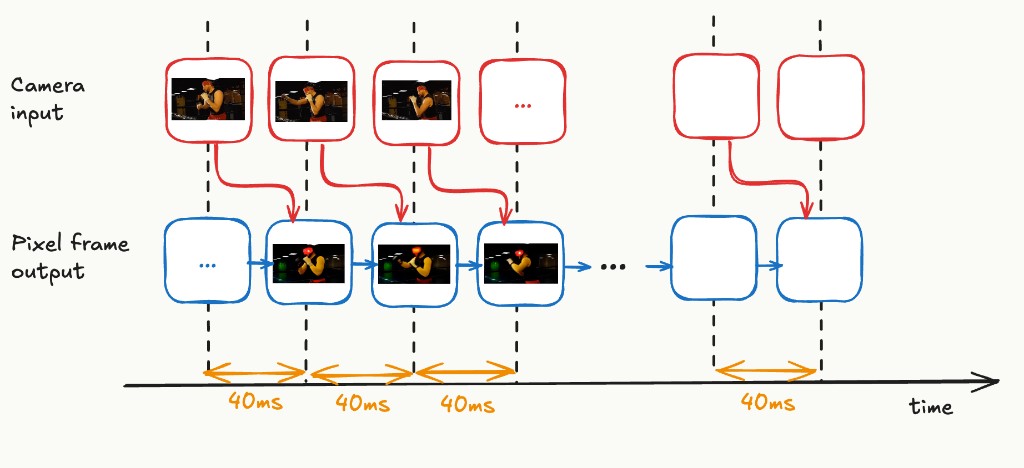
The Problem
Most modern video models such as MovieGen, Wan 2.1, Veo 3, and LTX-Video operate in a compressed latent space. They generate a latent frame in each autoregressive (AR) step. This is similar to how a large language model generates a text token every step. Typically, each latent frame corresponds to multiple pixel frames.
For the variational autoencoder (VAEs) used by video models like Wan 2.1, the “temporal stride” is 4, meaning that each latent frame encodes 4 pixel frames. So in each AR step, the video model produces 4 pixel frames at once.
With the help of existing literature and engineering techniques, it seems plausible to bring the per-AR-step latency down to ~40ms. However, if we simply speed up current architectures, which decompress each latent frame into 4 pixel frames, our latency diagram looks like the image below.
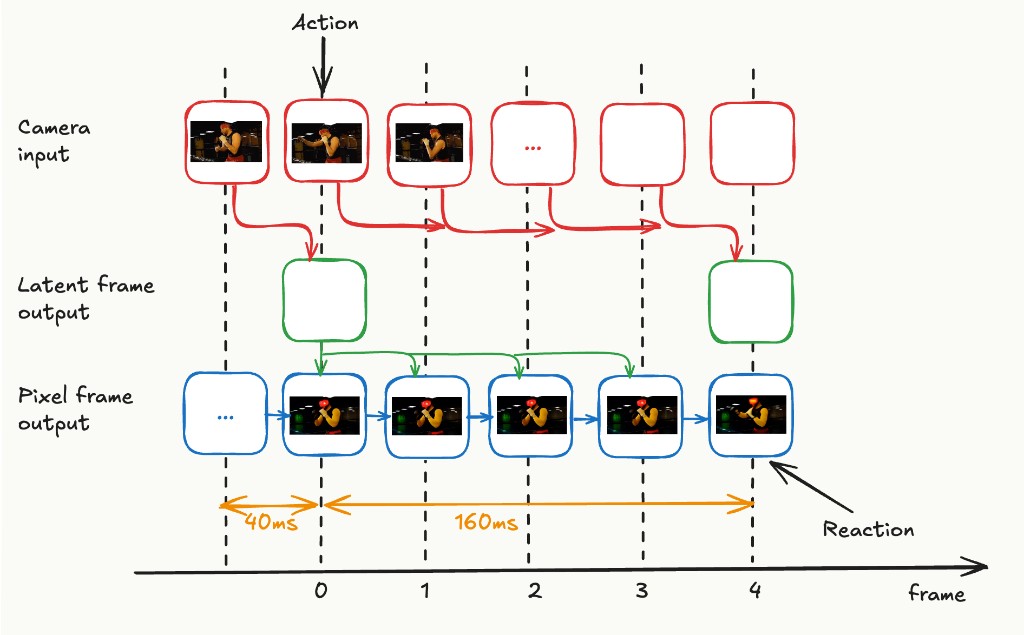
We can produce latent frames quickly enough, but the 4 pixel frames from each latent will span 160ms (4 × 40ms), and new camera input can only be incorporated at the next AR step. So the effective input-to-output latency is 160ms. The central problem is:
How do we use existing models to generate one pixel frame per AR step, while incorporating the latest input?
Existing Work
Several recent research efforts have tackled real-time video generation. We will discuss the ones most relevant to us here.
CausVid was one of the first and most comprehensive works toward building a real-time streaming AR video model. It shows how to distill the bidirectional Diffusion transformer (DiT) based Wan 2.1 video model into a causal AR model using Diffusion Forcing and Distribution Matching Distillation.
CausVid's asymmetric distillation carries out two changes at once: (1) converting the model from bidirectional to causal AR, and (2) reducing the number of denoising steps from 50 to 4. CausVid achieves a throughput of roughly 9.4 FPS on a single GPU with a time-to-first-frame of 1.3 seconds. However, its default chunk size (=5) is large, meaning new input cannot be reflected until the entire chunk is processed. Recent works, like Self Forcing and Context Forcing, have shown how the CausVid recipe can be improved for enhanced quality.
StreamDiffusionV2 builds on CausVid and Wan 2.1 with system-level optimizations: SLO-aware batch and block scheduling, pipeline parallelism, a rolling KV cache inspired by Self Forcing, and a streaming VAE design. Crucially, it demonstrates that the CausVid recipe works even when producing a single latent frame per AR step. It achieves roughly 58 FPS with a 14B-parameter model and roughly 65 FPS with a 1.3B model on 4xH100 GPUs using a single denoising step.
MirageLSD by Decart is one of the first publicly demonstrated system to achieve a per-pixel-frame latency of 40ms (24 FPS) for video generation. Like CausVid, it builds on Diffusion Forcing for causal generation, and presumably uses shortcut distillation to reduce the number of denoising steps to 1. On the systems side, MirageLSD employs custom CUDA “mega kernels”, fused GPU kernels that combine multiple operations into a single launch to avoid the overhead of repeated kernel launches, redundant memory loads, and inter-kernel synchronization, along with architecture-aware model pruning to maximize tensor-core utilization on NVIDIA Hopper GPUs. MirageLSD also does extensive work on ensuring that generation can run indefinitely without quality degradation, introducing a “history augmentation” technique where the model is fine-tuned on corrupted input histories to learn to correct accumulated artifacts. While this is critical for production use, we consider error accumulation out of scope for this post and focus only on the latency problem.
Finally, several distillation techniques are being developed to improve single-step generation quality, including consistency distillation, rectified flow, and shortcut distillation. For video-to-video scenarios specifically, the camera input already provides substantial information that could simplify the generation task.
For the remainder of this post, we assume the engineering challenge of achieving one AR step every 40ms is solvable, and focus solely on the problem posed by temporal compression in the latent space.
How to Generate One Pixel Frame per Step
Why not use a 2D VAE?
The simplest solution would be to go back a generation in video models, for example to Stable Video Diffusion, and use a 2D VAE which does not compress the time dimension at all. That way, the model would naturally generate one pixel frame every AR step.
However, without temporal compression, the number of tokens increases 4x (for temporal stride 4). This increases attention compute by 16× (since attention is quadratic in sequence length) and memory requirements by 4×. The quality of models based on 2D VAEs is also significantly worse than modern 3D VAE models. Moreover, it's unclear how to distill a model trained on a 3D VAE into one based on a 2D VAE — the latent spaces have different distributions and dimensionalities.
Our Idea: Predict one pixel frame at a time, then discard the rest
The next simplest idea is to use a model like CausVid but only keep one pixel frame from each generation, feeding the already-committed pixel frames back as conditioning for subsequent predictions. Here is how we propose to make this work.
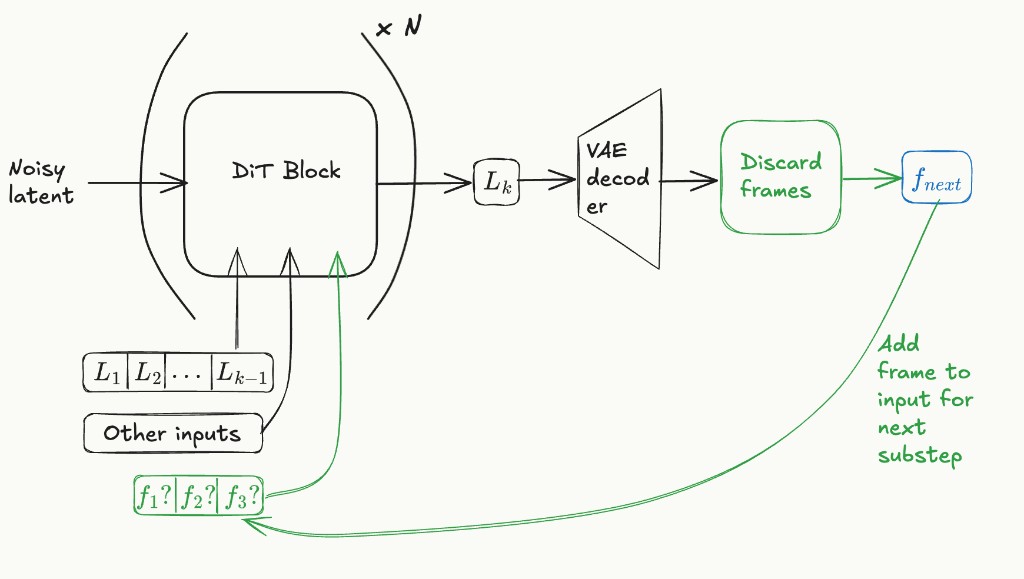
Current AR block diffusion video models have the structure shown below:
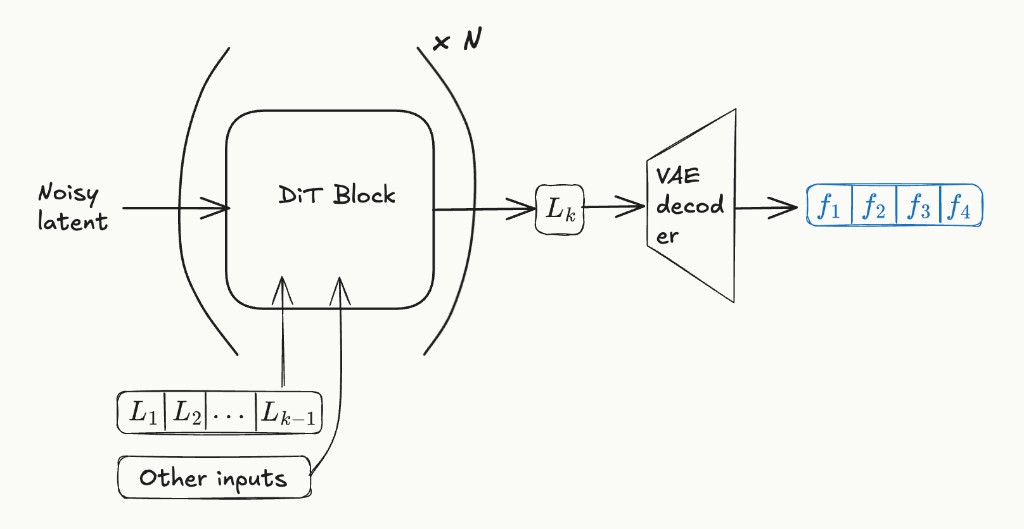
In the figure above, \(L_i\) is the \(i\)-th latent frame. To produce latent \(L_k\), the AR model starts with a noisy latent and passes it through a diffusion transformer (DiT). The noisy latent tokens can attend to tokens from past latents via block-causal masking.
We propose to modify this structure to accept an optional input of up to 3 pixel frames, as shown in the figure below. The idea is to make the AR model predict the next pixel frame instead of the next latent frame. Since the model still works in latent space, it still predicts a full latent frame, but we discard all decoded pixel frames except the one we need. Once a pixel frame is generated, we append it to the optional pixel frame input for the next step. We do not update the internal VAE decoder cache until we have generated all 4 pixel frames in a group. At that point, we update the decoder cache, clear the pixel frame inputs, and append the latent to the history.
Architecture Changes
A typical DiT block looks like this:
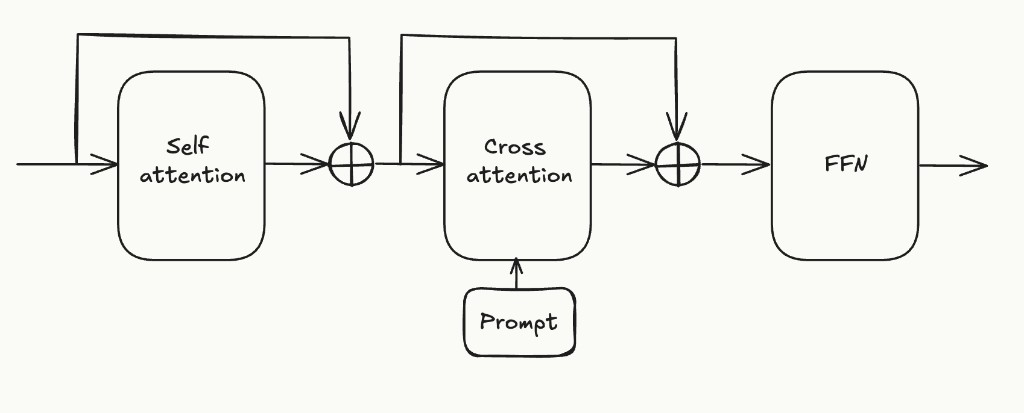
We propose adding a cross-attention layer for the optional pixel frame inputs like this:
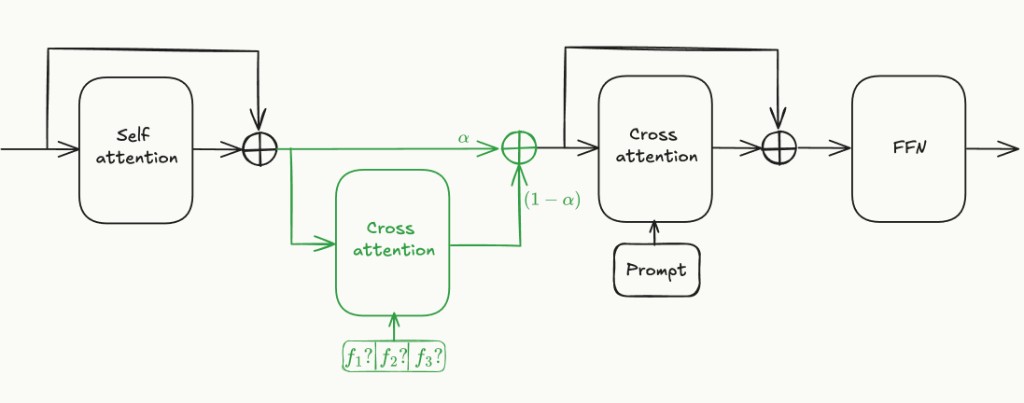
The pixel frames are embedded by passing them through a pretrained 2D image VAE encoder, patchifying the resulting latent map, and linearly projecting it into the DiT's hidden dimension.
The \(\alpha\) parameter used above is a parameter used for annealing during training. Once the model is trained, it is permanently set to 0.5.
Training
We start from a pretrained StreamDiffusionV2/CausVid checkpoint. The new cross-attention layers are randomly initialized. Training has three phases:
Phase 1 — Annealing (\(\alpha: 1 \rightarrow 0.5\)): We start with \(\alpha = 1\), so the model ignores the random cross-attention layers and behaves identically to the baseline. We linearly anneal \(\alpha\) to 0.5 over training. At each step, for a target latent \(L_n\), we sample \(k \in \{0, 1, 2, 3\}\) uniformly and train the model to predict \(L_n\) given:
- The latent history \((L_0, \ldots, L_{n-1})\) via self-attention
- The first \(k\) ground-truth pixel frames from group \(n\) via cross-attention (Note that these are available from the training data videos)
The loss is the standard diffusion or DMD objective applied to \(L_n\).
Phase 2 — Fine-tuning (\(\alpha = 0.5\), fixed): Continue training until convergence.
Phase 3 — Pixel loss training (\(\alpha = 0.5\), fixed): Since, we are independently decoding using the VAE decoder every time, it's likely that there would be jitter between the new pixel frame computed and the last frame. To minimise this we propose post-training with a pixel-mismatch loss, which would penalise the latent decoding incorrectly to known frames. Given a predicted latent \(\hat{L}_n\) conditioned on \(k\) pixel frames, we decode \(\hat{L}_n\), we propose to use the loss:
\[ \mathcal{L}_{\text{pixel}} = \sum_{i=0}^{k+1} \left\| \text{Dec}(\hat{L}_n)_{4n+i} - f_{4n+i} \right\|_2^2 \]
This loss is backpropagated through the decoder into the DiT, directly encouraging the model to produce latents whose decoding is consistent with the committed pixel frames.
Inference: A Concrete Example
Suppose we have committed latent frames \(L_0, \ldots, L_{n-1}\) and are now generating the pixel frames for group \(n\) — i.e., the 4 pixel frames \((f_{4n}, f_{4n+1}, f_{4n+2}, f_{4n+3})\). Let's call the optional pixel frame inputs \((\tilde{f}_{4n}, \tilde{f}_{4n+1}, \tilde{f}_{4n+2})\). These are initialised to None at the beginning. Inference works as follows:
- Sub-step \(j = 0\): The model predicts \(\hat{L}_n\) given only the latent history \((L_0, \ldots, L_{n-1})\) and no pixel frames. The VAE decoder produces 4 tentative frames. We commit the first one as \(\tilde{f}_{4n}\) and discard the other 3.
- Sub-step \(j = 1\): The model predicts \(\hat{L}_n\) given latent history and the committed pixel frame \((\tilde{f}_{4n})\). If the model has learned well, the decoder output is approximately \((\tilde{f}_{4n}, \hat{f}_{4n+1}, \hat{f}_{4n+2}, \hat{f}_{4n+3})\). We commit \(\hat{f}_{4n+1}\) as \(\tilde{f}_{4n+1}\) and discard the other 3.
- Sub-step \(j = 2\): Same pattern. The model sees \((\tilde{f}_{4n}, \tilde{f}_{4n+1})\), and the decoder output is approximately \((\tilde{f}_{4n}, \tilde{f}_{4n+1}, \hat{f}_{4n+2}, \hat{f}_{4n+3})\). We commit \(\hat{f}_{4n+2}\).
- Sub-step \(j = 3\): The model sees \((\tilde{f}_{4n}, \tilde{f}_{4n+1}, \tilde{f}_{4n+2})\), and the decoder output is approximately \((\tilde{f}_{4n}, \tilde{f}_{4n+1}, \tilde{f}_{4n+2}, \hat{f}_{4n+3})\). We commit \(\hat{f}_{4n+3}\).
Now all 4 pixel frames are committed. We encode them with the 3D VAE encoder to get \(L_n\), append it to the latent history, update the VAE decoder cache, clear the pixel frame buffer, and proceed to group \(n + 1\).
Extension to Video-to-Video
The above describes the text-to-video case. For video-to-video, where the model transforms an incoming video stream in real time, we need an additional conditioning pathway for the input video. A natural approach is to add another cross-attention layer that injects the input frame, encoded via the same 2D image VAE, into each DiT block. This is similar to how Wan 2.1 handles image conditioning in its I2V and VACE variants, and conceptually close to ControlNet-style conditioning.
Conclusion
We have presented our working model for how real-time video streaming models can be implemented using existing open-source components, primarily CausVid, Wan 2.1, and StreamDiffusionV2. The core idea is simple: add a cross-attention mechanism that conditions the DiT on partial pixel frames from the current group, enabling the model to predict and commit one pixel frame every 40ms while retaining a 3D VAE backbone.
There is still significant work needed to validate this approach empirically, in particular whether the model can reliably learn to predict latents that decode consistently with already committed pixel frames, and whether the exposure bias from using ground-truth frames during training is manageable. Techniques like Self Forcing could help here.
Our project is still a work in progress. Reach out if you would like to join us on this journey.